Trong thực tế, nếu tài nguyên của máy tính không là vấn đề thì ta nên sử dụng hết tất cả feature set dùng vào quá trình training và prediction. Ngược lại, việc giảm bớt được một lượng lớn feature sao cho performance của mô hình không bị ảnh hưởng nhiều nhờ vậy mà tính toán nhanh hơn sẽ là lựa chọn mà ta luôn nhắm tới.
Tiếp tục mini course, sau khi đã có predictive model cơ bản, ta sẽ tiến hành phân tích sâu hơn về việc lựa chọn feature và model tuning. Làm sao ta có thể biết trước feature mà mình tạo ra có độ tin cậy cao mà không cần phải đưa vào training? Làm sao để giảm gánh cho quá trình tính toán bằng cách loại bỏ những feature “vô dụng”? Làm sao tìm được các thông số phù hợp để mô hình cho ra kết quả dự đoán tối ưu? Tất cả sẽ được đề cập trong mục này.
Feature evaluation
Để đánh giá một feature, tôi xin giới thiệu 3 độ đo gồm Correlation, AUC và Coverage. Ta sẽ tìm hiểu từng độ đo và áp dụng lên một vài feature ta đã tính được. Cũng như kiểm chứng xem các độ đo này liệu có hiệu quả.
Correlation

Pearson correlation coefficient là độ đo quen thuộc đối với dân toán thống kê, dùng để tính độ tương quan tuyến tính giữa hai biến ngẫu nhiên. Nếu độ tương quan càng cao thì trị tuyệt đối của độ đo này càng lớn. Công thức được tính như sau:
![\rho_{X, Y} = corr(X, Y) = \frac{cov(X, Y)}{\sigma_X \sigma_Y} = \frac{E[(X - \mu_X) (Y - \mu_Y)]}{\sigma_X \sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2C+Y%7D+%3D+corr%28X%2C+Y%29+%3D+%5Cfrac%7Bcov%28X%2C+Y%29%7D%7B%5Csigma_X+%5Csigma_Y%7D+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29+%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X+%5Csigma_Y%7D&bg=ffffff&fg=000000&s=0&c=20201002)
AUC – Area Under the Curve



Nguồn: http://www.navan.name/roc/
| Predicted Class | |||
| Actual Class | Yes | No | |
| Yes | a | b | |
| No | c | d | |
Với confusion matrix (ma trận nhầm lẫn), ta có các thông tin:
- a:TP (true positive) – mẫu mang nhãn dương được phân lớp đúng vào lớp dương.
- b:FN (false negative) – mẫu mang nhãn dương bị phân lớp sai vào lớp âm.
- c:FP (false positive) – mẫu mang nhãn âm bị phân lớp sai vào lớp dương.
- d:TN (true negative) – mẫu mang nhãn âm được phân lớp đúng vào lớp âm.
Trong đó,
- TPR (true positive rate) = TP/P = TP/(TP + FN), còn gọi là sensitivity hay recall.
- FPR (false positive rate) = FP/N = FP/(FP + TN)
Để plot được AUC ta sẽ thay đổi threshold [0.5, 0.55, 0.6, 0.61, 0.7, etc] để gán nhãn 0/1 khi ra quyết định phân lớp. Từ đó, ta sẽ có các confusion matrix và thu được cặp TPR/FPR tương ứng ở trên.
AUC càng cao nghĩa là khả năng phân lớp càng tốt.
Nếu dãy threshold thưa khi plot AUC sẽ có nhiều đường răng cưa, ta có thể điều chỉnh threshold có độ phân giải cao hơn để AUC được plot mịn hơn.
Tại sao ta có thể dùng AUC để đánh giá feature? Lý do, cách tính AUC khi cho input là cặp dãy số (x, y), hàm tính AUC sẽ sắp xếp tăng dần dựa vào biến x, sau đó sẽ tính nguyên hàm (tức diện tích trong không gian 2D) để cho ra giá trị AUC. Giả sử biến x là loại binary (0/1) và dãy số x giống hoàn toàn dãy số y thì AUC sẽ bằng 1. Nếu cho dãy số x là nghịch đảo của dãy số y thì AUC sẽ bằng 0. Như vậy, AUC sẽ nằm trong khoảng [0, 1] nếu quan hệ giữa x, y có tương quan.
Bạn có thể tham khảo hàm tính AUC của sklearn ở 2 link sau:
Coverage
Dùng kiểm tra xem feature đang xét có bị Null nhiều hay không. Một feature mà có quá nhiều Null thì cũng không mang lại nhiều giá trị khi ra quyết định.
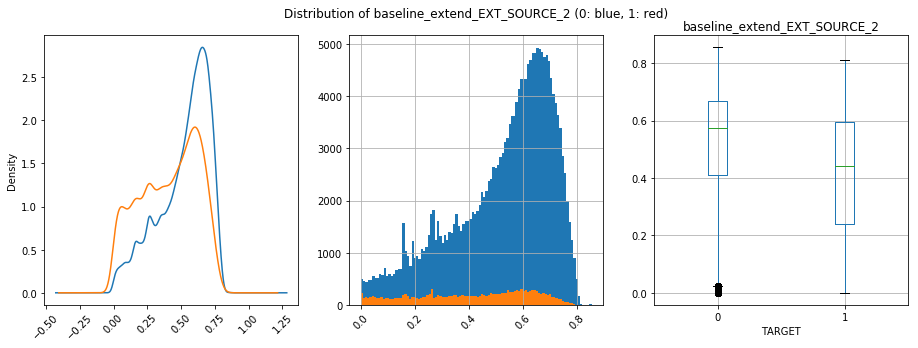
Ngoài ra, ta có thể plot feature tính được đem so với giá trị label (Histogram, Boxplot, KDE plot). Nếu phân bố của phân lớp càng tách biệt chứng tỏ feature có khả năng phân lớp cao.
Cả 3 metrics được tính theo hàm bên dưới
def my_auc(y_score, y_true, flexible_sign=True):
# filter NaN
idx = np.isfinite(y_score)
xxx = y_score[idx]
yyy = y_true[idx]
# if label not only 1s/0s
if yyy.std() > 0.0:
auc = metrics.roc_auc_score(y_score=xxx, y_true=yyy)
else:
auc = 0.5
# for evaluation only
if (auc < 0.5) & (flexible_sign):
auc = 1.0 - auc
return auc
def feature_evaluate(pdf_feat_label, ls_feat=None):
out_res = {
"feat_name": [],
"auc": [],
"corr": [],
"coverage": []
}
# calculate correlation
pdf_corr = pdf_feat_label[["TARGET"] + ls_feat].corr()
for feat in ls_feat:
out_res["feat_name"].append(feat)
out_res["auc"].append(my_auc(pdf_feat_label[feat], pdf_feat_label["TARGET"]))
out_res["corr"].append(pdf_corr.loc[feat, "TARGET"])
out_res["coverage"].append((~pdf_feat_label[feat].isna()).mean())
#
pdf_res = pd.DataFrame(out_res)
pdf_res = pdf_res[["feat_name", "auc", "corr", "coverage"]].sort_values(by="auc", ascending=False)
pdf_res.set_index("feat_name", inplace=True)
return pdf_res
Từ danh sách feature important rút ra được sau khi train với XGBoost model, ta thử đo 3 metrics này lấy từ top 5 và tail 5 để xem có phản ánh đúng feature important khi đưa vào model hay không



Ta thấy, feature tốt như prev_app_NAME_PRODUCT_TYPE_walk_in_max, baseline_extend_EXT_SOURCE_2 đều có độ đo cao. Ngược lại, feature như credit_card_balance_AMT_DRAWINGS_CURRENT_min thì chỉ số không quá ấn tượng.
Điểm đáng chú ý, giữa prev_app_NAME_PRODUCT_TYPE_walk_in_max, baseline_extend_EXT_SOURCE_2, mặc dù có important cao hơn nhưng cả ba chỉ số của prev_app_NAME_PRODUCT_TYPE_walk_in_max đều thua baseline_extend_EXT_SOURCE_2. Điều này cho thấy, ta không nên loại bỏ ngay những feature có các độ đo thấp vì khi kết hợp với các feature khác chúng sẽ cho khả năng phân lớp cao hơn.
Như vậy, ta có thể sử dụng 3 chỉ số này để đánh giá chất lượng của feature nhanh chóng trước khi đưa vào training. Nếu thấy feature chưa được tốt, ta có thể remove ra khỏi feature set của mình hoặc “tune” lại một chút để đạt được giá trị tốt hơn. Ngoài ra, khi ta nắm bắt được loại feature cho chất lượng phân lớp tốt, ta sẽ cố gắng đi sâu hơn vào loại feature này để mong có thể tăng performance cho model của chúng ta.
Feature selection
Thông thường ta sẽ có các hướng tiếp cận sau:
- Forwarding: ta bắt đầu với tập feature rỗng, sau đó lần lượt add thêm feature vào tập này. Nếu thấy performance của model tăng ta sẽ tiếp tục quá trình này, ngược lại sẽ dừng lại.
- Backwarding: ta bắt đầu với toàn bộ tập feature, sau đó lần lượt remove từng feature khỏi tập này. Nếu thấy performance của model tăng hoặc giảm không quá nhiều, ta sẽ tiếp tục quá trình này, ngược lại nếu performance bị drop quá mạnh sẽ dừng lại.
- Hybridge: kết hợp cả 2 hướng trên
Trong mini course này, tôi sẽ áp dụng hướng “backwarding”. Các bước thực hiện như sau:
- Đặt: n là số lần lặp feature selection, k là số feature sẽ drop ở mỗi lần lặp, p là AUC sau mỗi lần train
- Train model với XGboost
- Lấy kết quả feature important sắp xếp giảm dần và loại ra k feature có giá trị thấp nhất
- Lưu lại performance hiện tại để so sánh với performance tiếp theo.
Nếu thấp hơn ngưỡng p sẽ dừng - Tiếp tục quá trình selection
Tuỳ theo số lượng feature và cài đặt hyper-parameter của model thì thời gian sẽ nhanh chậm khác nhau. Tôi đã thử phương pháp này để drop số lượng feature còn 900/1000 features (giảm được 10%). Nếu số lượng feature của bạn chỉ từ 500 đổ lại thì không nhất thiết phải áp dụng quá trình này.
XGBoost tuning
Để tuning model ta có thể làm theo các cách sau:
- Manual: lựa chọn các tham số dựa vào kinh nghiệm. Ví dụ, mỗi lần giảm learning_rate thì performance của model tăng thì ta sẽ giữ lại thông số cho kết quả tốt và tiến hành thay đổi các thông số khác.
- Grid Search: tạo bảng kết hợp giữa các tham số. Nhược điểm của cách này là bùng nổ tổ hợp dẫn đến quá trình training chậm. Ví dụ, bạn chỉnh learning_rate = [0.1, 0.25, 0.5], max_depth = [4, 6, 8] thì chương trình sẽ tiến hành thử sai 3 * 3 = 9 lần. Nếu mỗi lần train mất 10 phút thì với cách này ta sẽ tốn 90 phút ~ 1h30 (trường hợp không sử dụng multi-threading).
- Random search: cũng sử dụng Grid search, nhưng sẽ kết hợp một cách ngẫu nhiên với giới hạn số lượng các phép thử (link paper).
- Khác: các thuật toán có thể tham khảo như Bayesian Optimization, optimization algorithms
Ví dụ phương pháp Grid search bằng thư viện sklearn. Với mỗi tham số, bạn có thể điền dãy giá trị mà bạn muốn thực nghiệm. Kết thúc quá trình tìm kiếm, ta sẽ nhận được tổ hợp hyper-parameter tốt nhất.
param_grid = {
"objective": ["binary:logistic"],
"booster": ["gbtree"],
"max_depth": [5, 6, 7], # default: 3 only for depthwise
"n_estimators": [5], # default: 500
"learning_rate": [0.025], # default: 0.05
"subsample": [0.8],
"colsample_bytree": [0.8], # default: 1.0
"colsample_bylevel": [0.8], # default: 1.0
"random_state": [1],
'min_child_weight': [11],
#
"silent": [True],
'seed': [1]
}
xgb_model = xgb.XGBClassifier()
grid_search = GridSearchCV(xgb_model, param_grid, n_jobs=16,
cv=StratifiedKFold(n_splits=5, shuffle=True, random_state=1),
scoring='roc_auc',
verbose=2)
grid_result = grid_search.fit(pdf_data[ls_features], pdf_data["TARGET"])
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
# ta có thể sử dụng grid_search để predict
y_test_pred = grid_search.predict_proba(X_kaggle_test)[:, 1]
Tính cho tới thời điểm kết thúc bài viết này thì AUC của tôi đặt được trên Kaggle là 0.79, kém leaderboard khoảng 0.01 điểm.

Để tìm hiểu chi tiết nội dung trong bài viết, ta có thể tham khảo những đường link bên dưới:

Một suy nghĩ 1 thoughts on “DS-mini: Feature evaluation and model tuning”