Feature engineering là gì
“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering.”
— Andrew Ng, Machine Learning and AI via Brain simulations
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.”
— Dr. Jason Brownlee from machinelearningmastery.com
Như vậy, feature engineering là tác vụ cần thiết trong quá trình xây dựng predictive model, rất tốn thời gian và công sức đòi hỏi phải có kiến thức ngành. Lý do, ta không thể đưa dữ liệu thô (raw data) trực tiếp vào bất kỳ mô hình Machine Learning nào. Nên mục tiêu của chúng ta cần làm là rút trích các đặc trưng (features) từ dữ liệu thô ban đầu này.
Vậy thế nào là một feature? Ví dụ, để nhận diện người bạn gặp là người quen hay người lạ, ta sẽ dựa vào các feature như dáng đi, màu tóc, quần áo, mắt, mũi, miệng của người đó. Trong bài toán home credit, feature có thể là các thông tin profile của người đi vay như độ tuổi, giới tính, lương hằng tháng, có bao nhiêu con, có sở hữu bất động sản không, etc.
Không nói nhiều lý thuyết nữa, ta hãy bắt tay vào feature engineering cho bảng application. Ta bắt đầu với bảng này vì nó chứa đầy đủ ID của user cả tập train và tập test, thuận tiện cho quá trình join features cũng như phân chia train/validation/test set.
Bắt đầu với kiểu binary
Link: report_application_train.csv (10 dòng đầu tiên) 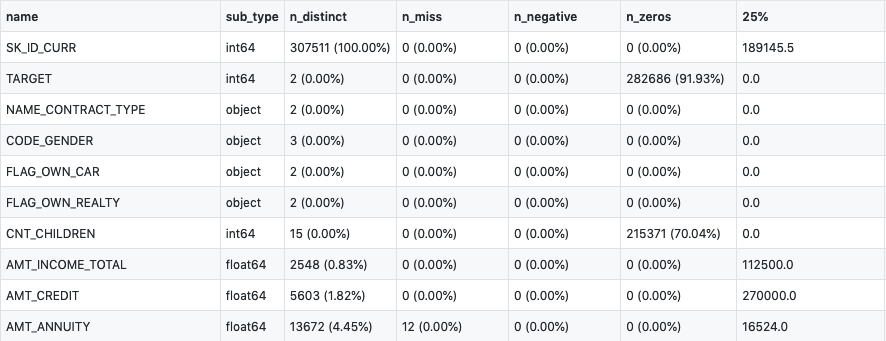
Nhìn vào cột sub_type và n_distinct, ta thấy sub_type chứa kiểu dữ liệu của thuộc tính đang xét (int64, object, float64), n_distinct cho biết có bao nhiêu giá trị riêng biệt trong số dòng dữ liệu đang xét. Hai cột này giúp ích rất nhiều trong việc xử lý và rút trích feature . Ví dụ, SK_ID_CURR (n_distinct) = 307511 (100.00%). Đây là profile của user, ta thấy không có dữ liệu bị trùng lặp, ta có thể xác định đây là bảng chứa thông tin của từng user và có thể sử dụng thông tin trong bảng để làm feature. Hay TARGET (n_distinct) = 2 (0.00%) đây là nhãn dữ liệu chỉ có 2 giá trị dùng làm nhãn trong quá trình training model.
Vậy kiểu dữ liệu binary (nhị phân) sẽ có n_distinct = 2 (0.00%). Đối với sub_type = int64, ta có thể sử dụng luôn giá trị trong cột dữ liệu này
# đổi tên cho thuộc tính
for cname in ls_binary_column:
feat_name = "is_" + cname
pdf_data[feat_name] = pdf_data[cname]
# ví dụ tên sau khi đổi
"is_FLAG_PHONE"
"is_FLAG_EMAIL"
"is_REG_REGION_NOT_LIVE_REGION"
"is_REG_REGION_NOT_WORK_REGION"
"is_LIVE_REGION_NOT_WORK_REGION"
Còn sub_type = object thì phải biến đổi một chút để đưa về dạng số như vậy mô hình của chúng ta mới có thể học được.
# dictionary này lấy từ quá trình phân tích dữ liệu
dict_default_val = {
"NAME_CONTRACT_TYPE": ['Cash loans', 'Revolving loans'],
"CODE_GENDER": ['M', 'F', 'XNA'],
"FLAG_OWN_CAR": ['Y', 'N'],
"FLAG_OWN_REALTY": ['Y', 'N'],
"EMERGENCYSTATE_MODE": ['Yes', 'No'],
}
for cname in ls_obj_binary_column:
# lấy giá trị mặc định để biến đổi sang giá trị 1
default_val = dict_default_val[cname][0]
# biến đổi category sang binary
feat_name = "is_" + cname
select_features.append(feat_name)
pdf_data[feat_name] = pdf_data[cname].apply(lambda x: int(x == default_val))
# ví dụ tên sau khi đổi
"is_NAME_CONTRACT_TYPE"
"is_CODE_GENDER"
"is_FLAG_OWN_CAR"
"is_FLAG_OWN_REALTY"
"is_EMERGENCYSTATE_MODE"
Biến đổi categorical thành one-hot vector
Kiểu dữ liệu categorical có thể xác định bằng sub_type = object. Đầu tiên, ta cần lấy ra các giá trị unique trong thuộc tính categorical. Sau đó, biến đổi các giá trị này thành feature one-hot. Ví dụ, NAME_INCOME_TYPE có các giá trị unique sau:
- Working
- State servant
- Commercial associate
- Pensioner
- Unemployed
- Student
- Businessman
- Maternity leave
dict_onehot_values = {
"NAME_TYPE_SUITE": ["Unaccompanied", "Family", "Spouse, partner", "Children", "Other_A", "Other_B", "Group of people"],
"NAME_INCOME_TYPE": ["Working", "State servant", "Commercial associate", "Pensioner", "Unemployed", "Student", "Businessman", "Maternity leave"],
"NAME_EDUCATION_TYPE": ["Secondary / secondary special", "Higher education", "Incomplete higher", "Lower secondary", "Academic degree"],
"NAME_FAMILY_STATUS": ["Single / not married", "Married", "Civil marriage", "Widow", "Separated", "Unknown"],
"WALLSMATERIAL_MODE": ["Stone, brick", "Block", "Panel", "Mixed", "Wooden", "Others", "Monolithic"],
}
for cname in ls_cate_cols:
# lấy danh sách giá trị unique
ls_vals = dict_onehot_values[k][cname]
for val in ls_vals:
# đặt tên cho feature
new_name = "{}_{}".format(cname, val)
# biến đổi one-hot dựa vào giá trị unique
pdf_data[new_name] = pdf_data[cname].apply(lambda x: int(x == val))
Các thuộc tính có sub_type = float64, do chỉ có 1 dòng dữ liệu trong application nên ta có thể dùng trực tiếp giá trị từ dữ liệu
Biến đổi các thuộc tính đặc biệt
Nếu tìm hiểu kỹ ý nghĩa các cột thuộc tính, ta sẽ phát hiện rằng các thuộc tính ngày như DAYS_BIRTH, DAYS_REGISTRATION, DAYS_ID_PUBLISH, DAYS_LAST_PHONE_CHANGE, DAYS_EMPLOYED chứa toàn giá trị âm. WHAT?
Ví dụ, ta xem số liệu thống kê của thuộc tính đồng thời visualize thử phân bố của DAYS_BIRTH

pdf_train["DAYS_EMPLOYED"].describe() # output count 307511.0000 mean -16036.9951 std 4363.9886 min -25229.0000 25% -19682.0000 50% -15750.0000 75% -12413.0000 max -7489.0000 Name: DAYS_EMPLOYED, dtype: float64
Lý do giá trị trong DAYS_BIRTH mang số âm là vì dữ liệu được lưu tại thời điểm tương đối so với thời gian nộp hồ sơ. Ví dụ, người đi nộp hồ sơ tại năm 2019, nếu họ sinh năm 1980 thì dữ liệu sẽ được lưu thành (1980 – 2019) * 365 = -14235.
Ta sẽ biến đổi DAYS_BIRTH sang số năm bằng cách chia cho -365 ngày. Khi đó, ta sẽ có phân bố mới như bên dưới.
(pdf_train["DAYS_BIRTH"] / -365).describe() # output count 307511.0000 mean 43.9370 std 11.9561 min 20.5178 25% 34.0082 50% 43.1507 75% 53.9233 max 69.1205 Name: DAYS_BIRTH, dtype: float64

Tương tự, ta sẽ biến đổi cho các thuộc tính DAYS_REGISTRATION, DAYS_ID_PUBLISH, DAYS_LAST_PHONE_CHANGE. Riêng thuộc tính DAYS_EMPLOYED ta sẽ xử lý trước một bước.
Quan sát thuộc tính DAYS_EMPLOYED ta thấy có một giá trị outlier là 365243
pdf_train["DAYS_EMPLOYED"].describe() # output count 307511.0000 mean 63815.0459 std 141275.7665 min -17912.0000 25% -2760.0000 50% -1213.0000 75% -289.0000 max 365243.0000 Name: DAYS_EMPLOYED, dtype: float64

Kiểm tra, ta sẽ thấy giá trị anomaly 365243 chiếm khá nhiều trong bảng
# check anomaly
anom = pdf_train[pdf_train["DAYS_EMPLOYED"] == 365243]
non_anom = pdf_train[pdf_train["DAYS_EMPLOYED"] != 365243]
print("Tỉ lệ phần trăm TARGET <span id="mce_SELREST_start" style="overflow:hidden;line-height:0;"></span>của non-anomalies: {}".format(100 * non_anom["TARGET"].mean()))
print("Tỉ lệ phần trăm TARGET của anomalies: {}".format(100 * anom["TARGET"].mean()))
print("Số lượng anomalies là {}".format(len(anom)))
# output
Tỉ lệ phần trăm TARGET của non-anomalies: 8.65997453765
Tỉ lệ phần trăm TARGET của anomalies: 5.39964604327
Số lượng anomalies là 55374
Ta xử lý bằng cách tạo 1 feature check xem DAYS_EMPLOYED có phải là anomaly không. Sau đó, replace giá trị này bằng NaN và thực hiện biến đổi sang giá trị năm như DAYS_BIRTH
# Create an anomalous flag column
pdf_train["DAYS_EMPLOYED_ANOM"] = pdf_train["DAYS_EMPLOYED"] == 365243
# Replace the anomalous values with nan
pdf_train["DAYS_EMPLOYED"] = pdf_train["DAYS_EMPLOYED"].replace({365243: np.nan})
# Calculate years employed
pdf_train["YEARS_EMPLOYED"] = pdf_train["DAYS_EMPLOYED"] / -365
Lúc này, YEARS_EMPLOYED sau khi biến đổi sẽ trông hợp lý hơn

Kết
Bảng dữ liệu application có 122 columns, trong đó 2 column ta không dùng tới là SK_ID_CURR và TARGET. Nếu làm theo hướng dẫn trên ta đã rút trích ra được khoảng 210 features, cũng khá nhiều phải không nào. Để hiểu thêm chi tiết các bước thực hiện như thế nào, các bạn có thể tham khảo notebook này.
Các bước thực hiện FE ở các bảng khác, ta có thể tham khảo các link bên dưới:

Một suy nghĩ 1 thoughts on “DS-mini: Feature engineering (application)”