
Trong bài viết này, ta sẽ khảo sát bài toán Rút trích thông tin (Information extraction – IE), một nhánh nghiên cứu nâng cao thiên về rút trích thông tin ngữ nghĩa trong văn bản. Từ đây, ta sẽ có nhiều ứng dụng cho nhiều domain như Web mining (rút trích tên người nổi tiếng, sản phẩm đang hot, so sánh giá sản phẩm, nghiên cứu đối thủ cạnh tranh, phân tích tâm lý khách hàng), Biomedical, Business intelligent, Financial professional (đánh giá thị trường từ các nguồn khác nhau: giá xăng dầu tăng giảm, thông tin chiến tranh, chính trị giữa các nước, điều luật mới trong thị trường kinh doanh), Terrism event (sử dụng vũ khí gì, đối tượng tấn công là ai).
Sau các bước tiền xử lý thiên về từ vựng và cú pháp như tách câu, tách từ, phân tích cú pháp, gán nhãn từ loại. Từ IE ta sẽ đơn giản hóa thành các bài toán con gồm: Rút trích tên thực thể (Named entity recognition – NER: people, organization, location), phân giải đồng tham chiếu (Coreference resolution) và Rút trích quan hệ giữa hai thực thể (Relation extraction – RE: founderOf, headQuarteredIn). Các mô hình khi thực nghiệm sẽ được đánh giá thông qua các chỉ số Precision, Recall, F1-score. Dưới đây là một ví dụ về rút trích quan hệ trong câu.
In 1998, Larry Page and Sergery Brin founded Google Inc.
Output sẽ là
FounderOf(Larry Page, Google Inc.) FounderOf(Sergery Brin, Google Inc.) FoundedIn(Google Inc., 1998)
Thông tin này sẽ được sử dụng cho các hệ thống khác như Search engine, Database management để cung cấp dịch vụ tốt hơn cho người dùng.
Thách thức
Bị nhập nhằng tên thực thể như JFK mang nhãn người đối với “John F.Kennedy” hay mang nhãn địa điểm đối với “JFK International Airport” hay những từ viết tăng mang nhiều nghĩa tương ứng. Hay giữa hai thực thể có thể xuất hiện nhiều mối quan hệ khác nhau nên việc chọn được mối quan hệ chính xác là một thách thức lớn.
State-of-the-art về độ chính xác:
- NER: 90% F1-score
- RE: 77% F1-socre
Lịch sử
Bài toán được khởi xướng từ những năm 70s (DeJong’s FRUMP program). Sau này đã thành lập Message Understanding Conferences – MUC vào những năm 90s.
Ban đầu, MUC-4 sử dụng predefined template slots/value (Date, Location, Type, Stage of execution, Instrument type, Name, Description, Number). Đến MUC-6 mới sử dụng template-independent gồm NER, đồng tham chiếu (Coreference resolution), RE. Các tác vụ con này giải quyết được các bài toán cho từng domain cụ thể.
Hướng tiếp cận Rule-base: sử dụng pattern trong ngôn ngữ được định nghĩa bằng tay để matching information trong văn bản. Cách làm này cho hiệu suất cao đối với domain cụ thể nhưng tốn sức và đòi hỏi phải có domain knowledge mới xây dựng được.
Hướng tiếp cận máy học thống kê (statistical machine learning): bằng cách tách nhỏ thành các bài toán nhỏ hơn như NER chính là classification, ta có thể áp dụng các phương pháp Machine learning quen thuộc như SVM, Maximum Entropy Models, HMM, Conditional Random Fields để giải quyết.
Tuy nhiên, các hướng tiếp cận đòi hỏi cấu trúc cần rút trích phải được định nghĩa trước như name entities, loại quan hệ, template slots. Trong một số trường hợp, ta không hề biết cấu trúc này ra sao trong tập corpus khổng lồ. Vì vậy ta cần một hướng tiếp cận khác để khai thác tập dữ liệu này. Đã có nhiều nghiên cứu về động đất sử dụng phương pháp Unsupervised learning nhưng cho đến hiện nay thì kết quả vẫn còn nhiều giới hạn.
Một hướng tiếp cận khác đó là hệ thống sẽ cố gắng rút trích tất cả các quan hệ thực thể được cho là hữu ích thu thập từ Web. Output của hệ thống không chỉ gồm tên của quan hệ mà cả mô tả chi tiết của quan hệ đó. Những tên tuổi nổi tiếng là TextRunner, Woe, ReVerb.
Named Entity Recognition
Đây là bài toán con được xem là tiền xử lý cho bài toán phức tạp hơn là Relation Extraction, Question answering, Search engine entity-oriented. Được công bố đầu tiên vào năm 1995 tại MUC-6, kể từ đó NER nhận được nhiều sự quan tâm từ cộng đồng hơn. Danh sách NER cũng được liệt kê trong MUC-6 như person, organization, location, date, time, monetary, percentages.
Hướng tiếp cận Rule-based
Cách cheating đơn giản đó là ta sử dụng gazetteer (danh sách tên người, địa điểm, tổ chức đã được gán nhãn sẵn) để search ngay trong văn bản cho trước.
Rule-based trong NER hoạt động như sau: một tập các rule được định nghĩa sẵn hay tự động phát sinh. Mỗi token trong văn bản sẽ được biểu diễn dưới dạng tập các feature. Văn bản đầu vào sẽ đem so sánh với tập rule này, nếu rule match thì sẽ thực hiện rút trích.
Một rule như vậy gồm pattern + action. Pattern thường là regular expression định nghĩa trên tập feature của token. Khi pattern này match thì action sẽ được kích hoạt. Action có thể là gán nhãn entity cho chuỗi token, thêm nhãn start/end cho entity, hay xác định nhiều entity cùng lúc. Ví dụ để match danh từ riêng “Mr. X” trong đó X là từ viết hoa ám chỉ tên người ta có rule như sau:
(token="Mr." orthography type=FirstCap) -> person name
Bên trái là regular expression sẽ match chuỗi gồm 2 token, token đầu tiên là “Mr.”, token thứ hai là từ viết hóa. Bên phải là action gán nhãn chuỗi này là person name. Phương pháp này còn được sử dụng trong Part-of-Speech taggin – POS.
Dĩ nhiên, ta sẽ bắt gặp trường hợp một chuỗi text match với nhiều rules cho trước. Để giải quyết việc này người ta thường sắp xếp ràng buộc các rule sao cho chuỗi text sẽ được duyệt và kiểm tra trước khi action được kích hoạt.
Để tự động phát sinh luật, ta có thể phân thành hướng tiếp cận top-down và bottom-up. Tuy nhiên, ta vẫn cần gán nhãn entity cho tập dữ liệu trước. Top-down sẽ định nghĩa rule tổng quát có thể match càng nhiều instance càng tốt, sau đó thuật toán sẽ lặp nhiều lần để tìm tập giao của các rule tổng quát này để sinh ra các rule cụ thể hơn. Bottom-up thì định nghĩa các rule match rất ít instance trong tập dữ liệu và dần dần tổng quát hóa lên các rule tổng quát hơn cho hệ thống.
Hướng tiếp cận Statistical learning
Đây là hướng tiếp cận được sử dụng nhiều nhất. NER được chuyển về bài toán sequence labeling. Bài toán được định nghĩa như sau: cho trước tập các chuỗi quan sát ký hiệu 

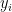
Để gán nhãn, ta thường dùng BIO notation (trước đó dùng trong text chunking). Với mỗi entity kiểu T, ta có hai nhãn B-T và I-T. B-T là begin type T, I-T là inside type T. Ngoài ra, ta còn có nhãn O cho biết outside name entity. Ta có thể tham khảo ví dụ bên dưới
Steve Jobs was a co-founder of Apple Inc. B-PER I-PER O O O O B-ORG I-ORG
Các phương pháp phân lớp được sử dụng:
- Hidden Markov Model – HMMs (generative model): Nymble của BBN sử dụng Maximum Likelihood Estimation sao cho cực đại hóa
, trong đó
là tất cả các câu trong ngữ liệu,
là nhãn tương ứng với các chuỗi câu đó. Để train mô hình ta có thể dùng dynamic programming.
- Maximum Entropy Markov Models – MEMMs (discriminative model): nghiên cứu bởi McCallum, cho độ lỗi thấp hơn HMM. Lúc này nhãn
. Vậy bài toán trở thành cực đại hóa xác suất
. Các thuật toán dùng để train gồm Generalized Itera-tive Scaling (GIS), Improved Iterative Scaling (IIS) và limited memoryquasi-Newton như L-BFGS (thường được dùng để cài đặt).
- Conditional Random Fields – CRFs (discriminative model): được nghiên cứu bởi Lafferty, điểm khác biệt so với MEMMs ở chỗ nhãn
. Trong đó,
. Ta cũng dùng L-BFGS để train. Do CRF tính toán
bằng cách lấy tổng tất cả các khả năng nhãn của chuỗi
nên train CRF sẽ tốn kém hơn MEMMs. Sarawagi và Cohen đề xuất semi-Markov CRF gán nhãn lên segment của
và rút trích feature trên segment này giúp cho quá trình train được giảm tải và được chứng minh mang lại hiệu suất cao hơn thuật toán CRF truyền thống.
Relation Extraction
Bài toán này phát hiện và mô tả quan hệ ngữ nghĩa giữa các entity trong văn bản. Ví dụ
Facebook co-founder Mark Zuckerberg
sẽ rút trích được quan hệ sau:
FounderOf(Mark Zuckerberg, Facebook)
Bài toán này hầu hết dựa trên định nghĩa của Automatic Content Extraction (ACE), chương trình này tập trung vào quan hệ hai ngôi (binary relation). Hai entity trong quan hệ này còn được gọi là arguments. ACE sẽ định nghĩa tập cha và tập con các quan hệ như physical, personal/social, employment/affiliation. ACE phân biệt rõ giữa relation extraction (xác định quan hệ ngữ nghĩa dựa trên toàn bộ những gì thu thập được từ corpus) và relation mention extraction (chỉ quan tâm đến quan hệ được chỉ định trước).
Để giải quyết bài toán này, ta thường chuyển về trực tiếp bài toán classification. Cho trước cặp entity đồng xuất hiện trong câu, ta cần phân loại quan hệ giữa hai thực thể này thuộc một trong các quan hệ được định nghĩa trước. Để đơn giản, ta chỉ quan tâm đến hai thực thể trong một câu, bài toán có thể mở rộng thành quan hệ giữa hai thực thể nằm ở các câu khác nhau.
Feature engineering đặc biệt quan trọng trong bài toán này. Từ đây, ta có thể áp dụng phương pháp Kernel sử dụng các thuật toán training SVM để thực hiện phân lớp. Kernel ở đây có thể xây dựng dựa trên chuỗi các từ, dependency trees, dependency paths, parse trees. Cả hai phương pháp feature-based và kernel-based đều cần một tập ngữ liệu rất lớn để huấn luyện. Do đó, có một hướng khác là weakly supervised learning có thể rút trích relation từ corpus lớn mà không đòi hỏi nhiều quá trình gán nhãn ban đầu. Họ sử dụng boostrapping đối với tập dữ liệu nhỏ trước, sau đó dần dần tìm ra các relation mới cũng như các pattern tìm được trong corpus. Nổi bật trong hướng giải quyết này có Snowball. Ngoài ra, ta có hướng tiếp cận distant supervision dựa trên các relation biết trước lấy từ tập tri thức như Freebase.
Hướng tiếp cận feature-based classification
Ta thực hiện thông qua hai bước: một xác định xem hai entity này có quan hệ hay không, hai nếu có thì đó là quan hệ gì. Trong corpus, hai entity có nhãn quan hệ với nhau được gọi là positive example, ngược lại là negative example. Thuật toán thường dùng là SVM và logistic regression. Một số feature được sử dụng trong quá trình feature engineering:
- Entity features: father, mother, brother, sister thường có quan hệ family với nhau.
- Lexical contextual features: từ founder xuất hiện giữa hai entity thì có khả năng chúng có quan hệ FounderOf.
- Syntactic contextual features: có thể trích ra từ parse tree như từ founded có subject là entity1, object là entity2 thì khả năng chúng có quan hệ FounderOf là rất cao.
- Background knowledge: Chan và Roth nghiên cứu việc sử dụng Wikipedia để hỗ trợ relation extraction. Nếu hai argument đồng xuất hiện trong bài viết Wikipedia thì nội dung của bài viết đó sẽ được sử dụng để kiểm tra hai entity này có quan hệ hay không. Một ví dụ khác là word cluster, nếu chúng ta có thể gom các từ như IBM và Apple thành một cluster ta có thể định nghĩa ra entity mới cao hơn.
- Graph feature: Jiang và Zhai đề xuất nhãn quan hệ bằng cách sử dụng graph
. Trong đó,
là tập đỉnh,
là tập các cạnh có hướng,
là hàm gán nhãn cho các đỉnh. Với mỗi đỉnh
là tập các thuộc tính (attribute) liên kết với đỉnh
.
. Trong đó, 0 cho biết đỉnh
Sử dụng Kernel method
Ý tưởng của Kernel đó là thực hiện phép inner product của hai vector trong không gian nhiều chiều. Việc làm này tương đương với phép tính độ tương tự giữa hai vector. Điểm hay ở Kernel đó là hai vector này không cần phải được ánh xạ vào không gian nhiều chiều đó nhưng vẫn thực hiện được phép inner product này. Kernel dùng trong relation extraction gồm:
- Sequence-based kernel: Bunescu và Mooney đề xuất kernel dựa trên tìm đường đi ngắn nhất của dependency path. Nếu hai dependency path có cùng độ dài thì sẽ có similarity bằng 1, ngược lại bằng 0 và đây cũng là điểm yếu của kernel này. Ngoài ra, họ còn đề xuất lấy feature từ các subsequence để so sánh cho sequence đang xét. Tập dữ liệu ở đây là protein-protein test.
- Tree-based kernel: ý tưởng như trên cũng xét độ tương tự thông qua substructure. Nếu hai parse tree có cùng nhiều subtree thì khả năng hai quan hệ này là tương đồng nhau. Sau này, Culotta và Sorensen mở rộng bằng cách sử dụng dependency parse tree. Zhang tiếp tục áp dụng convolution tree kernel được đề xuất bởi Collins và Duffy để rút trích quan hệ. Kernel này lại được cải tiến bởi Qian và đạt được hiệu suất state-of-the-art khoảng 77% (F1-measure) trên tập dữ liệu benchmark ACE 2004.
- Composite kernel: kết hợp nhiều kernel lại với nhau thành composite. Ví dụ syntatic kernel, dependency path kernel kết hợp với argument kernel.
Sử dụng Weakly supervised learning method
Cả hai phương pháp bootstraping và distant supervision đều sản sinh ra tập nhiễu. Do đó, để đảm bảo hiệu suất, ta cần thực hiện feature selection và pattern filtering cẩn thận.
- Bootstraping: Agichtein và Gravano phát triển hệ thống Snowball cho tác vụ relation extraction. Ta bắt đầu với một tập seed entity pair có liên quan đến relation đích. Ví dụ, nếu relation đích đang nhắm đến là HeadquarteredIn, ta có thể sử dụng seed pair như
. Cho trước tập ngữ liệu lớn, ta tìm các cặp entity này đồng xuất hiện trong văn bản. Ta giả định rằng nếu hai entity này đồng xuất hiện gần với relation đích thì nhiều khả năng đây chính là relation mà ta đang tìm. Ví dụ, ta có thể tìm thấy các mẫu câu như “Google’s headquarters in Mountain View”, “Redmond-based Microsoft” và rút trích ra được pattern “ORG’s headquarters in LOC”, “LOC-based ORG”. Với pattern tìm được, ta lại có thể tìm kiếm tiếp
có điểm tương đồng với realtion HeadquarteredIn. Ta thêm entity pair này vào seed relation instance và lặp lại quá trình. Điểm quan trọng là làm sao ta lọc ra các relation không liên quan.
- Distant supervision: sử dụng Wikipedia hoặc Freebase, Mintz đề xuất ý tưởng rằng nếu hai entity tham gia vào một relation thì bất kỳ câu nào chứa hai entity này sẽ có khả năng mô tả relation đang tìm. Do giả định này không lúc nào đúng nên ông cũng đã thêm vào feature rút trích ra từ các câu này để làm giàu thêm feature. Kết quả đạt được khoảng 70-74% ở F1 measure.
Nguồn dữ liệu
- Automatic Content Extraction (ACE)
- Message Understanding Conference – MUC
- Conference on Computational Natural Language Learning – CoNLL
- BioCreAtIvE
- GENIA corpus
Nguồn thư viện
- Apache OpenNLP
- brat rapid annotation tool
- LingPipe’s Competition
- NLTK
- Stanford CoreNLP
- MAchine Learning for LanguagE Toolkit
- IEPY
- 100 Best GitHub: Relation Extraction
Systems
- Sentence segmentation
- Tokenization
- POS
- Parsing
- Dependency parsing
- NER
- Coreference
- Relation extraction
- Document similarity
Nguồn tham khảo
- Information extraction from text
- A Review of Relation Extraction
- Open Information Extraction using Wikipedia
- Nymble: a High performance learning Name-finder
- Snowball: Extracting Relations from Large Plain-Text Collections
- Slide Relation extraction II: Distant supervision
- Introduction to Natural Language Processing (NLP) 2016
- Introduction to Information Retrieval
- What is Relation Extraction- Stanford NLP
- Combining Distant and Partial Supervision for Relation Extraction
- Giải quyết bài toán đồng tham chiếu trong văn bản tiếng việt dựa vào SVM
- BRAT: a Web-based Tool for NLP-Assisted Text Annotation

Anh ơi cho e hỏi một chút ạ. Em đang làm luận văn về trích rút metadata từ thư viện khoa hoc (văn bản tiếng việt). E đã có tìm hiểu thì thấy rằng ít bài báo nghiên cứu về cái đấy, chủ yếu là trích rút metadata từ bài báo khoa học tiếng anh dùng Rule. Mà dữ liệu đầu vào của e bao gồm sách, báo, đề tài,.. có cách nào trích rút được không a. E định dùng svm phân lớp câu, nhưng thấy ko khả quan lắm hix. Thanks a
ThíchThích
Em thử đọc bài báo này http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.11.9202&rep=rep1&type=pdf
ThíchĐã thích bởi 1 người
Hi anh, Em đang làm luận văn về truy xuất thông tin ấy. a có bài báo hay bài viết nào nói về cách sử dụng các mô hình trong truy xuất thông tin không ạ. Em đang làm mà thấy mông lung quá anh ạ. hix
ThíchThích
Rất cảm ơn về bài viết của anh!
ThíchThích
Chào anh! Em làm luận văn về trích xuất thông tin từ dữ liệu mạng xã hội. Rút trích các thông tin như tiêu đề, nội dung, hình ảnh. Anh có kinh nghiệm hay bài báo nào liên quan cho em xin tham khảo ạ!
ThíchThích
xuất trích có nhiều cấp độ:
– thô: văn bản dưới dạng html/xml có thể lập trình để crawl về (dùng scrapy hoặc beautifulsoup)
– Văn phạm: phân tích từ vựng, cú pháp, ngữ pháp
– Ngữ nghĩa: phân lớp, gom nhóm văn bản, nhận diện thực thể từ, phân tích quan hệ ngữ nghĩa các ngữ…
Em nên tìm hiểu ứng dụng hoặc nhờ thầy/cô hướng dẫn gợi ý hướng đi tìm tài liệu, dữ liệu, các ứng dụng liên quan nhé.
ThíchThích
Rất cảm ơn anh!
ThíchThích
Cho mình hỏi mình muốn trích rút các tên riêng của người trong văn bản bạn có tài liệu nào không cho mình tham khảo với, cảm ơn nhiều.
ThíchThích
bạn tìm từ khoá Name Entity Recognition (NER) nhé, bạn có thể bắt đầu với các bài viết này
https://www.kdnuggets.com/2018/08/named-entity-recognition-practitioners-guide-nlp-4.html
https://www.commonlounge.com/discussion/2662a77ddcde4102a16d5eb6fa2eff1e
ThíchThích