
Trong bài viết này, ta sẽ tìm hiểu thế nào là một mô hình ngôn ngữ (language modeling). Làm sao để xây dựng được một mô hình ngôn ngữ từ tập các mẫu câu của một ngôn ngữ bất kỳ (Anh, Việt, Nhật, …). Mô hình ngôn ngữ ban đầu được ứng dụng trong nhận dạng tiếng nói (speech recognition) và đã được áp dụng vào trong những tác vụ khác liên quan trong lĩnh vực Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) như gán nhãn từ loại (tagging), phân tích cây cú pháp (parsing), dịch máy (machine translation), …
Tại sao chúng ta cần mô hình ngôn ngữ? Lý do thứ nhất, mô hình này cung cấp cho bạn thông tin về phân bố xác suất tiền nghiệm (prior distribution) 
p(tối nay được đi chơi rồi vui quá) > p(quá rồi vui được đi chơi nay tối)
nhờ vậy mà ta xác định được câu “tối nay được đi chơi rồi vui quá” sẽ phù hợp hơn với ngôn ngữ tiếng Việt hơn câu hai “quá rồi vui được đi chơi nay tối”. Thứ hai, các kĩ thuật liên quan đến ước lượng tham số cho mô hình thông qua tập dữ liệu huấn luyện cho trước được sử dụng trong các mô hình khác như Hidden Markov Model, Natural Language Parsing. Và cuối cùng, đây là một trong những cơ sở kiến thức để các bạn đọc hiểu được các bài viết liên quan đến Long short-term memory (LSTM).
Đặt vấn đề
Giả sử ta có một ngữ liệu (corpus) thu thập được từ các trang web như vnexpress, baomoi, hay foody. Ngữ liệu là tập dữ liệu gồm các câu (sentence) cho một ngôn ngữ xác định. Tiếp theo, ta định nghĩa 

Mục tiêu của chúng ta là xây dựng được mô hình có khả năng tính toán xác suất của một câu bất kỳ thuộc về một ngôn ngữ cụ thể

Trong đó, 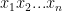




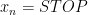
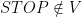
con meo nhay STOP con meo keu STOP keu meo con STOP meo meo meo STOP STOP ...
Từ đây, ta đặt 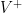
Định nghĩa một cách toán học một xíu. Một mô hình ngôn ngữ gồm tập hữu hạn từ vựng 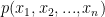

và

Như vậy 
Ta có thể định nghĩa xác suất trên bằng công thức đơn giản như sau

Với 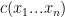



Công thức này thật sự đơn giản khi bắt đầu, nhưng ta cần biết được hạn chế của nó khi tử số bằng không. Tử số bằng không có nghĩa là câu được tính không nằm trong ngữ liệu huấn luyện. Điều này dẫn đến mô hình không có khả năng tổng quát hoá, trong khi mục tiêu của Machine Learning là đi tổng quát hoá để có thể dự đoán được bất kỳ mẫu dữ liệu nào không có trong ngữ liệu. Ta sẽ đi khắc phục nhược điểm này ở các phương pháp sẽ được đề cập ở mục tiếp theo.
Markov Models
Ý tưởng chính của mô hình Markov là giả định xác suất của đối tượng hiện hành chỉ phụ thuộc vào 


Xét một chuỗi các biến ngẫu nhiên 


Như vậy, với chuỗi có dạng 
= 
= 

(1.1) là công thức chuẩn suy ra được từ xác suất đồng thời (chain rule), (1.2) suy ra được từ công thức này với giả định rằng đối tượng thứ 
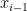

Tương tự, ta có mô hình Markov bậc hai (second-order Markov)
=
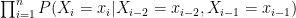
Để thuận tiện cho xử lý, ta đặt 

Để tính xác suất xuất hiện của đối tượng 

ta thực hiện các bước sau
- Khởi tạo
, và
- Phát sinh đối tượng
- Nếu
thì ta trả về chuỗi
. Ngược lại, ta gán
và quay lại bước 2.
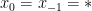
Như vậy, ta đã có một mô hình có thể phát sinh được một chuỗi có chiều dài bất kỳ
Trigram Language Models

Trong thực tế, ta có nhiều cách để xây dựng mô hình ngôn ngữ, nhưng ta sẽ tập trung vào mô hình cơ bản nhất là Trigram Language Models. Mô hình này chính là Markov bậc hai như đã đề cập ở phần trên.
=
Định nghĩa cho mô hình này gồm một tập hữu hạn từ vựng
với mỗi trigram 
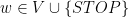


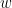

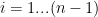

và đặt
Các tham số 
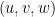


Ta có thể xem ví dụ bên dưới cho câu “Việt nam là đất nước tươi đẹp”

Maximum-Likelihood Estimates
Để ước lượng xác suất cực đại, ta định nghĩa 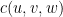

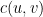


Ví dụ cho câu chó gặm xương ta có

Công thức ước lượng thật đơn giản phải không nào. Tuy nhiên, công thức trên vướng phải những vấn đề sau:
- Do số lượng từ vựng của chúng ta trong thực tế là khá lớn khoảng
từ vựng, như vậy ta sẽ có khoảng
các khả năng của tham số
- Và tham số không xác định khi
.

Để giải quyết vấn đề này, ta có thể áp dụng một số phương pháp như
Linear interpolation
Ta định nghĩa trigram, bigram, và unigram như sau

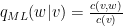

Trong đó, ta lưu ý 

Ý tưởng của phương pháp linear interpolation (nội suy tuyến tính) đó là sử dụng cả ba tham số trên bằng cách định nghĩa trigram estimate như sau

Trong đó, 
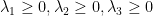
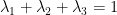
Chúng còn được gọi là trọng số trung bình (weighted average) cho từng tham số 
_ Log-likelihood
Ta chia ngữ liệu ban đầu thành ba tập: training, testing, developing (ví dụ tỷ lệ tương ứng là 60%, 10%, 20%). Ta định nghĩa 

=

=

Mục tiêu của chúng ta là chọn được các giá trị 

_ Bucketing
Ta định nghĩa lại các tham số



Trong đó 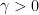
Discounting Methods
Đây là một hướng tiếp cận khác để ước lượng tham số

với mọi

Với mọi bigram 

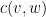

trong đó ![\beta \in [0, 1]](https://s0.wp.com/latex.php?latex=%5Cbeta+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002)

Từ đây, ta định nghĩa
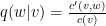
Ví dụ, sau khi áp dụng công thức trên, ta có bảng tương tự bên dưới (
 |
 |
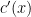 |
 |
|---|---|---|---|
| con | 48 | ||
| con,chó | 15 | 14.5 | 14.5/100 |
| con,mèo | 11 | 10.5 | 10.5/100 |
| con,gà | 10 | 9.5 | 9.5/100 |
| con,bò | 5 | 4.5 | 4.5/100 |
| con,tàu | 2 | 1.5 | 1.5/100 |
| con,con | 1 | 0.5 | 0.5/100 |
| con,cóc | 1 | 0.5 | 0.5/100 |
| con,heo | 1 | 0.5 | 0.5/100 |
| con,mồi | 1 | 0.5 | 0.5/100 |
| con,thoi | 1 | 0.5 | 0.5/100 |
Với mọi ngữ cảnh 
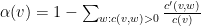
Từ bảng ví dụ trên ta có

Lúc này 


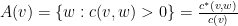
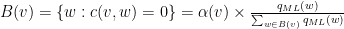
Theo ví dụ trên ta có

và 
Tổng quát hoá cho trường hợp trigram
Với mọi bigram




Trong mô hình này, để ước lượng tham số

Ta thực hiện bằng cách lặp qua các giá trị 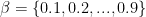
Đánh giá mô hình này như thế nào
Làm thế nào để đánh giá chất lượng của một mô hình ngôn ngữ? Một trong những phương pháp phổ biến đó là perplexity (độ hỗn độn).
Giả sử ta có tập các câu để test (held-out: không nằm trong tập training) 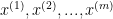



Ta tính xác suất 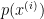

giá trị thu được từ phép tính trên càng cao thì chất lượng của mô hình càng tốt đối với dữ liệu chưa hề thấy trong tập training.
Perplexity được định nghĩa như sau

trong đó

Theo công thức trên, nếu giá trị của perplexity càng nhỏ, mô hình ngôn ngữ xây dựng được càng tốt.
Trong thực nghiệm của Goodman, ông đưa ra biểu đồ cho thấy perplexity là 74 đối với trigram model, 137 cho bigram model, và 955 cho unigram model. Mô hình này đơn giản chỉ gán xác suất 1/50,000 cho từng từ với bộ từ vựng 50,000. Như vậy trigram model cho ta giá trị đánh giá mô hình ngôn ngữ tốt hơn bigram và unigram.
Nguồn tham khảo
Language models
Language modeling a billion words
Music Language Modeling with Recurrent Neural Networks

Anh ơi thế còn các language model khác như tf-idf, word2vec, GloVe thì sao ạ?
ThíchThích
language model là phân bố xác suất của chuỗi các từ (câu) – p(w_1, w_2, …, w_m) = ? Các mô hình bạn vừa đề cập là dạng vector hoá phục vụ cho so sánh và tìm kiếm, không phải language model.
ThíchThích
Cám ơn bài chia sẽ của anh,
Hiện em đang học Machine Translation. Em có đọc qua kiến trúc encoder-decoder. Nếu em nói Language Model là quá trình Encoder (bao gồm Việc biểu diễn Words và training để tạo ra Context Vector) thì đúng không a?
ThíchThích
code trong encode-decode là biến dữ liệu dạng thô sang dữ liệu dạng vector.
language model là xét xác xuất của câu đang diễn đạt P(X) là bao nhiêu với X là chuỗi các từ
một bên là phương pháp, một bên là khái niệm nên ko thể đặt câu hỏi như trên
ThíchThích
Anh cho em hỏi chút với ạ. Mô hình ngôn ngữ cho truy hồi thông tin (Language models for information
retrieval) gồm những mô hình gì vậy ạ ? Em có tra trên gg và thấy các kq như mô hình ngôn ngữ thống kê unigram,bigram, n-gram, mô hình ngôn ngữ tài liệu, mô hình ngôn ngữ xác suất… Em k rõ lắm ạ , mong anh có thể giúp em trả lời câu hỏi này. Em cảm ơn anh ạ
ThíchThích