
Dùng để làm gì? Support vector machine (SVM) xây dựng (learn) một siêu phẳng (hyperplane) để phân lớp (classify) tập dữ liệu thành 2 lớp riêng biệt.
Siêu phẳng là cái gì? Một siêu phẳng là một hàm tương tự như phương trình đường thẳng, y = ax + b. Trong thực tế, nếu ta cần phân lớp tập dữ liệu chỉ gồm 2 feature, siêu phẳng lúc này chính là một đường thẳng.
Về ý tưởng thì SVM sử dụng thủ thuật để ánh xạ tập dữ liệu ban đầu vào không gian nhiều chiều hơn. Khi đã ánh xạ sang không gian nhiều chiều, SVM sẽ xem xét và chọn ra siêu phẳng phù hợp nhất để phân lớp tập dữ liệu đó.
Có ví dụ đơn giản nào không? Ta lấy ví dụ đơn giản về phân chia tập các quả bóng xanh và đỏ đặt trên một cái bàn. Nếu các quả bóng phân bố không quá đan xen vào nhau, ta có thể dùng một cây que dài để chia các quả bóng thành hai tập xanh và đỏ mà không động đến các quả bóng.
Lúc này, khi đưa một quả bóng mới đặt lên mặt bàn, bằng cách xác định nó nằm bên phía nào của cây que, ta có thể dự đoán màu sắc của quả bóng đó.
Vậy các quả bóng, cái bàn và cây que tượng trưng cho cái gì? Các quả bóng tượng trưng cho các điểm dữ liệu, màu xanh và đỏ tượng trưng cho 2 lớp. Cái bàn tượng trưng cho một mặt phẳng. Cây que tượng trưng cho một siêu phẳng đơn giản đó là một đường thẳng.
Điểm hấp dẫn ở đây đó là SVM có thể hình dung ra được đâu là siêu phẳng phù hợp nhất.
Đối với trường hợp phức tạp hơn thì sao? Thật ra dữ liệu ngoài thực tế rất phức tạp. Nếu các quả bóng xen lẫn vào nhau thì một cây que khó có thể phân lớp được.
Ta sử dụng thủ thuật: nhấc bổng cái bàn lên, nhanh chóng hất các quả bóng lên trời. Trong khi các quả bóng đang lơ lửng và nằm ở các vị trí thích hợp, ta dùng một mảnh giấy lớn để phân lớp các quả bóng đang lơ lửng này.
Nghe có vẻ gian dối? Không đâu, việc hất các quả bóng lên trời tương đương với việc ánh xạ tập dữ liệu ban đầu vào không gian nhiều chiều hơn. Trong trường hợp này, ta đi từ không gian 2 chiều đó là cái bàn vào không gian 3 chiều đó các quả bóng đang lơ lửng trên trời.
Làm sao SVM thực hiện được điều này? Bằng cách sử dụng một kernel, ta có thể đơn giản nâng dữ liệu ban đầu vào không gian nhiều chiều hơn. Mảnh giấy lớn lúc này cũng được gọi là một siêu phẳng, chỉ có điều đây là phương trình mặt phẳng chứ không phải phương trình đường thẳng.
Clip bên dưới sẽ minh họa cho thao tác trên của SVM
Việc ánh xạ này trong thực tế được thực hiện như thế nào? Quả bóng nằm trên mặt bàn có một vị trí cụ thể, ta dùng trục tọa độ để xác định vị trí này. Ví dụ, quả bóng nằm cách mép trái 20cm và cách mép dưới 50cm được thể hiện trên trục tọa độ (x, y) tương ứng là (20, 50). x và y chính là không gian hai chiều của quả bóng. Khi đưa lên chiều thứ 3 là z(x, y), ta có thể tính được tọa độ của z trong không gian 3 chiều dựa vào tọa độ x,y ban đầu.

Thuật ngữ margin trong SVM có nghĩa là gì? Margin là khoảng cách giữa siêu phẳng đến 2 điểm dữ liệu gần nhất tương ứng với các phân lớp. Trong ví dụ quả bóng và cái bàn, đó là khoảng cách giữa cây que và hai quả bóng xanh và đỏ gần nó nhất.
Điểm mấu chốt ở đây đó là SVM cố gắng maximize margin này, từ đó thu được một siêu phẳng tạo khoảng cách xa nhất so với 2 quả bóng xanh và đỏ. Nhờ vậy, SVM có thể giảm thiểu việc phân lớp sai (misclassification) đối với điểm dữ liệu mới đưa vào.
Tên gọi SVM xuất phát từ đâu? Trong ví dụ cái bàn và quả bóng, siêu phẳng cách đều với bóng xanh và bóng đỏ. Các quả bóng này chính là các điểm dữ liệu gọi là support vectors, vì chúng hỗ trợ (support) để dựng lên siêu phẳng.
Tại sao sử dụng SVM? SVM cho độ chính xác cao đối với tập dữ liệu có kiểu dữ liệu liên tục (continuous value), cùng với thuật toán cây quyết định là hai phương pháp thường được dùng để phân lớp dữ liệu. Tuy nhiên, không có mô hình phân lớp (classifier) nào là tốt nhất theo No Free Lunch Theorem. Thêm vào đó, việc lựa chọn kernel và diễn giải cho người dùng hiểu là một điểm trừ của SVM.
Có thư viện nào cho SVM? Hiện tại có rất nhiều thư viện cài đặt SVM. Một vài thư viện phổ biến như scikit-learn, MATLAB và dĩ nhiên là libsvm.
Strengths: có thể mô hình non-linear decision boundaries bằng cách sử dụng nhiều kernels khác nhau. Ít bị overfitting đặc biệt ở không gian high-dimensional.
Weaknesses: sử dụng nhiều RAM, trickier khi tuning do phải lựa chọn kernel phù hợp cho mô hình, khó scale khi tập dữ liệu quá lớn. Trong thực tế, random forests được sử dụng nhiều hơn SVM.
Nguồn tham khảo:

việc tính toán để tìm được khoảng cách margin lớn nhất trong thuật toán như thế nào addcos thể trình bày cụ thể được không ạ?
có ví dụ cụ thể nào không?
ThíchThích
Hi bạn, svm được chuyển đổi sang bài toán tối ưu Lagrange, mình thường sử dụng Matlab để thực nghiệm và ko đi sâu vào thuật toán, bạn có thể tham khảo note liên quan
Support Vector Machines http://cs229.stanford.edu/notes/cs229-notes3.pdf
ThíchĐã thích bởi 1 người
thầy cho em ít tài liệu về phần phân lớp dữ liệu trong SVM được ko ạ?
ThíchThích
Hi, em có thể tham khảo bài giảng này http://cs229.stanford.edu/notes/cs229-notes3.pdf
ThíchThích
Thầy ơi, thầy có tài liệu về phân loại ảnh dựa trên cây quyết định (decision tree) ko ạ? Thầy cho em xin đc ko thầy? Em cảm ơn thầy.
.
ThíchThích
em chuyển ảnh mxn thành 1xk (lấy mỗi dòng của ảnh ghép lại với nhau thành vector duy nhất, không còn dạng ma trận nữa) rồi áp dụng decision tree bình thường.
ThíchThích
Em chào thầy ẹ! em đang làm khóa luận có liên quan đến sử dụng SVM cho dự đoán chứng khoán. thầy cho e tài liệu về phần dự đoán của SVM được không ạ? em tìm tài liệu nhưng phần này rất ít. e cảm ơn thầy ạ
ThíchThích
em nên liên hệ với thầy hướng dẫn nhé, anh cũng không đi sâu vào mô hình này, chỉ áp dụng thư viện để thực nghiệm thôi. Nếu muốn tìm các bài báo hay tài liệu em có thể vào https://scholar.google.com.vn tìm với keyword là “svm stock prediction”
ThíchThích
cho em hỏi bài toán này áp dụng với các dữ liệu liên tục ? thầy giải thích cụ thể hơn được không ạ. Em có một bài toán phân lớp mà dữ liệu đầu vào các feature có thể có mối liên hệ với nhau thì dùng giải thuật này được không ạ, em muốn dùng một giải thuật ANN, giải thuật nào của ANN thì phù hợp bài toán của em ạ.
ThíchĐã thích bởi 1 người
Dữ liệu đầu vào có nhiều loại
http://blog.minitab.com/blog/understanding-statistics/understanding-qualitative-quantitative-attribute-discrete-and-continuous-data-types
Các thuật toán như SVM hay ANN đều cần thuộc tính là số liên tục để phân lớp (không phải danh mục, text)
ThíchThích
Cho em hỏi thêm chút ạ. Ví dụ em có bài toán mà đầu vào vector [12, 10000, 10 , 30, …] mà các số là các feature thể hiện một mặt của dữ liệu, mà các số đó em nghĩ là kết hợp với nhau (có mối quan hệ) để từ đó đưa ra phán đoán tốt nhất cho label ấy ạ. thì giải thuật ANN phù hợp với bài toán này ạ, em hỏi thêm nữa là các số có độc lệch về giá trị kiểu như 10, 20, 100000 thì có cần xử lý sao cho các giá trị gần khoảng lớn với nhau như chia cho bao nhiêu những giá trị feature thứ 2 chẳng hạn không anh.
Em cảm ơn anh nhiều :))
ThíchThích
Câu hỏi 1: em có thể giảm số chiều dữ liệu bằng PCA https://ongxuanhong.wordpress.com/2015/07/18/exploratory-data-analysis-giam-so-chieu-du-lieu/
Câu hỏi 2: em có thể chuẩn hóa feature https://en.wikipedia.org/wiki/Feature_scaling
ThíchThích
Em cảm ơn anh ạ, còn câu hỏi về giải thuật ANN nào phù hợp với bài toán mà các dữ liệu liên quan như em trình bày không ạ.
ThíchThích
Cơ bản là thuật toán Gradient Descent từ đó ta sẽ có các phương pháp tối ưu về tốc độ và độ chính xác http://cs231n.github.io/neural-networks-3/
ThíchThích
Em cảm ơn anh :))
ThíchThích
Anh ơi, cho em hỏi chút, em có đọc về sự khác biệt giữa deep learning và neural network thì deep learning là neural network with multi layer, có đúng không ạ. Một câu nữa là neural network có thể giải quyết các bài toán mà những thuật toán ML cổ điển có thể giải quyết nhưng vấn đề là tốn thời gian train, có phải không ạ.
Em cảm ơn
ThíchThích
1) deep learning là neural network with multi layer -> đúng một phần, phần còn lại phụ thuộc các phép biến đổi giữa các layer (CNN, RNN, LSTM, …)
2) neural network có thể giải quyết các bài toán mà những thuật toán ML cổ điển có thể giải quyết nhưng vấn đề là tốn thời gian train -> không đúng, lý do tuỳ bài toán và thuật toán mà thời gian train sẽ khác nhau (k-NN là một ví dụ), hơn nữa nếu NN có độ chính xác kém hơn các mô hình khác thì dĩ nhiên ta không xem NN giải quyết được vấn đề.
ThíchThích
cho em hỏi một chút, là những thuật toán ANN như CNN, RNN, LSTM, thì có phải là tạo ra để giải quyết những bài toán đặc trưng về xử lý ảnh hay ngôn ngữ tự nhiên không ạ, hay là nó sẽ giải quyết những bài toán tùy thuộc vào feature đầu vào.
ThíchThích
Do ANN là representation model, ta không cần làm feature engineering như các model khác. Và các thuật toán trên chỉ mang tính chất tham khảo để ta dựa trên đó áp dụng vào bào toán của chúng ta. Ta không bó hẹp phạm vi ứng dụng mà có thể áp dụng vào nhiều lĩnh vực khác tuỳ thuộc vào khả năng sáng tạo của nghiên cứu sinh.
ThíchThích
Em chào anh. Hiện tại em đang thực hiện đồ án tốt nghiệp với đề tài “Nhận dạng đối tượng dựa trên bộ tham số”. Cụ thể bài toán của em như sau:
– Một đối tượng có thể có nhiều chế độ hoạt động khác nhau.
– Các tham số của mỗi đối tượng là cố định (khoảng 7-8 tham số)
– Bộ dữ liệu được cung cấp có 164 đối tượng khác nhau và 302 chế độ hoạt động của các đối tượng naỳ.
– Khi hệ thống thu nhận được một bộ tham số, ta cần nhận dạng xem bộ tham số này là thuộc loại nào trong số các đối tượng đã biết.
Em đọc về bài viết SVM của anh, em thấy bài toán của em có thể áp dụng được multi-class, tuy nhiên, trong trường hợp số lớp cần được phân lớp là khá lớn. Anh có bổ sung hay hướng đi nào khác để em có thể tham khảo không ạ.
Em cám ơn anh!
ThíchThích
Chào em, với bài toán multi-classification, em có thể áp dụng kỹ thuật one-vs-all (quy về bài toán binary-classification) hoặc mô hình Neural Network, Naive Bayes với đầu ra là số lớp cần phân lớp (có thể gán nhãn từ 0-k) hay áp dụng các thuật toán clustering với số k bằng số đối tượng của tập dữ liệu.
ThíchThích
Anh ơi, cho em hỏi chút ạ:
Em đang đọc về SVM nhưng có vài điểm thắc mắc ạ, với những bài toán mà linear kernel của SVM không thể giải quyết thì SVM có Gaussian kernel giải quyết ( em đọc thì gaussian kernel không phải chỉ dùng mình trong SVM mà dùng chung cho ML) giúp giảm chiều của feature nhưng em không hiểu chính xác ý nghĩa của Gaussian kernel lắm, có một khái niệm nữa là kernel trick, giúp mở rộng chiều của feature giúp dễ dàng xác định mặt siêu phẳng trong SVM, em hỏi là 2 khái niệm kernel và kernel trick có khác hay liên quan không ạ, Em cảm ơn.
ThíchThích
Kernel dùng để tăng số chiều, ví dụ hàm x được nâng lên x^2 sau khi áp dụng kernel.
Kernel trick – trick ở đây là thủ thuật, không có nghĩa gì khác.
Gaussian là một trong số các kernel được sử dụng trong SVM http://crsouza.com/2010/03/17/kernel-functions-for-machine-learning-applications/
ThíchĐã thích bởi 1 người
vâng ạ, em cảm ơn anh
ThíchThích
Anh có thể giúp em lấy ví dụ về sử dụng kernel như thế nào trong SVM không ạ, ví dụ em có feature 2 chiều [[1,2],[3,4]] thì khi đó nếu áp dụng kernel dạng tuyến tính thì K=u.v (em không hiểu lắm là khi này thì u là x1[1,2] thì v sẽ là gì ạ) mà khi đó K sẽ là một giá trịi hay sẽ là một tập feature mới có chiều nhiều hơn tập dữ liệu cũ ạ. ( em có tìm hiểu nhưng vẫn chưa hiểu rõ lắm). Thêm một khái niệm inner product và dot product anh có thể giải thích cho em hiểu không ja.
em cảm ơn
ThíchThích
Anh cho em ví dụ tổng quát để em dễ hình dung.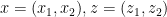




Cho
Polynomial Kernels
v sẽ là [3,4]. Ở đây, em chỉ có 2 feature vector nên K sẽ trả về 1 giá trị. Nếu em có nhiều hơn 2 feature, ta sẽ tính kernel K cho từng cặp vector để trả về một ma trận vuông với số chiều bằng số lượng vector hay còn gọi là Gram matrix.
Mục tiêu của chúng ta khi cho trước vector , ta đi tính feature mới
, ta đi tính feature mới  . Trong đó,
. Trong đó,  là số thành phần trong vector
là số thành phần trong vector  và
và  là số lượng vector có trong tập dữ liệu. Lúc này, thay vì giải bài toán ban đầu
là số lượng vector có trong tập dữ liệu. Lúc này, thay vì giải bài toán ban đầu  ta đi giải
ta đi giải 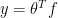 . Gram matrix được sử dụng tại đây, do
. Gram matrix được sử dụng tại đây, do ![f = (f_1, f_2, ..., f_m), i \in [1, m], f_i = K(x, x^i)](https://s0.wp.com/latex.php?latex=f+%3D+%28f_1%2C+f_2%2C+...%2C+f_m%29%2C+i+%5Cin+%5B1%2C+m%5D%2C+f_i+%3D+K%28x%2C+x%5Ei%29&bg=ffffff&fg=000000&s=0&c=20201002) . Tức là Gram matrix sẽ là đầu vào cho bài toán mới của chúng ta.
. Tức là Gram matrix sẽ là đầu vào cho bài toán mới của chúng ta.
Dot product (tích vô hướng): là tổng của tích các thành phần giữa 2 vector. Ý nghĩa dùng làm phép biến đổi nâng chiều trong Kernel.
Inner product (tích có hướng): cho biết mối tương quan giữa 2 vector. Tích 2 vector càng gần 1 thì 2 vector càng giống nhau ngược lại càng gần 0 thì 2 vector khác nhau. Ý nghĩa giảm bớt số chiều của Gram matrix khi ta quan sát thấy các vector trùng hoặc gần giống nhau.
ThíchThích
em hiểu rồi ạ, nhưng trong một số baì viết về kernel sử dụng gaussian kernel thì họ sử dụng hàm kernel là K(x,y) thì y người ta lấy là ma trận chuyển vị của x luôn thì có khác với việc sử dụng y như a nói ở trên không ạ.
ThíchThích
Không có gì khác, đây chính là trong Gram matrix.
trong Gram matrix.
ThíchĐã thích bởi 1 người
Thầy cho em hỏi chút. SVM phân 2 lớp thì input đầu vào dạng:
-1 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
-1 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
-1 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
+1 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
-1 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
-1 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
-1 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
-1 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
+1 5:1 18:1 19:1 39:1 40:1 63:1 67:1 73:1 74:1 76:1 80:1 83:1
Trong đố: +1, -1 là nhãn.
Nếu phân đa lớp cụ thể là 4 lớp thì cách input đầu vào như thế nào Thầy? Khi chạy vẫn chạy như 2 lớp hả Thầy. Em cảm ơn Thầy. Mong Thầy giải đáp
ThíchThích
E áp dụng one-vs-all sau đó lấy nhãn có xác xuất cao nhất làm kết quả cuối cùng
ThíchThích
Em cảm ơn Thầy. Thầy có thể giải thích qua cho em một chút được không?
ThíchThích
em đọc tài liệụ có một số chiến lược phân đa lớp với SVM: như OAR, OAO, Fuzzy OAO. Nhưng em không hiểu cách input dữ liệu để đưa vào chạy SVM. Phân đa lớp chạy giống phân 2 lớp đúng không Thầy.
ThíchThích
Đúng rồi e, e tạo ma trận Y(mxk) với m là số mẫu, k là số lớp. Mẫu nào thuộc lớp k_i thì thay nhãn bằng 1 ngược lại bằng 0. Tiếp tục thay nhãn cho các lớp còn lại trong ma trận Y.
Output sẽ là k model của svm. Khi phân lớp e chọn k model nào có xác xuất cao nhất so vs model còn lại https://www.youtube.com/watch?v=ZvaELFv5IpM
ThíchThích
Thầy! Em có mẫu dữ liệu trên web: http://www.cs.colorado.edu/~jbg/teaching/CSCI_5622/rank.train
Thầy có thể giải thích các thông số cho em chút được không?
1 qid:1 1:0.057239 2:0.000439 3:0.320218 4:1.000000 5:0.000000 6:0.000000 7:0.000000 # Terminator 3: Rise of the Machines
2 qid:1 1:-0.059483 2:0.051360 3:1.159401 4:0.000000 5:0.000000 6:0.000000 7:0.000000 # Sleuth
3 qid:1 1:-0.074544 2:-0.017120 3:0.669877 4:0.000000 5:1.000000 6:0.000000 7:0.000000 # Party, The
4 qid:1 1:0.034648 2:0.032045 3:0.809741 4:0.000000 5:0.000000 6:0.000000 7:1.000000 # Donnie Brasco
5 qid:1 1:-0.093370 2:0.098768 3:0.879673 4:0.000000 5:0.000000 6:0.000000 7:1.000000 # Gattopardo, Il
1 qid:2 1:0.012057 2:0.003951 3:-0.309169 4:1.000000 5:1.000000 6:0.000000 7:0.000000 # Hard Way, The
2 qid:2 1:-0.149849 2:-0.013608 3:0.949605 4:0.000000 5:0.000000 6:0.000000 7:1.000000 # Key Largo
3 qid:2 1:0.023352 2:0.025022 3:0.809741 4:0.000000 5:1.000000 6:0.000000 7:1.000000 # Yin shi nan nu
4 qid:2 1:-0.018065 2:0.039069 3:0.460082 4:0.000000 5:0.000000 6:0.000000 7:1.000000 # Silkwood
5 qid:2 1:0.023352 2:-0.001317 3:-0.588897 4:0.000000 5:1.000000 6:0.000000 7:1.000000 # Love Affair
1 qid:3 1:-0.006770 2:0.000439 3:0.040490 4:1.000000 5:0.000000 6:0.000000 7:0.000000 # F/X
2 qid:3 1:0.057239 2:0.002195 3:-0.728761 4:1.000000 5:0.000000 6:0.000000 7:0.000000 # League of Extraordinary Gentlemen, The
3 qid:3 1:0.019587 2:0.005707 3:-0.379101 4:1.000000 5:0.000000 6:0.000000 7:1.000000 # Program, The
4 qid:3 1:0.015822 2:-0.024143 3:-0.588897 4:1.000000 5:0.000000 6:0.000000 7:1.000000 # Rapid Fire
5 qid:3 1:0.049709 2:0.026777 3:0.250286 4:0.000000 5:0.000000 6:0.000000 7:1.000000 # Score, The
Em cảm ơn Thầy.
ThíchThích
Đây là movie ranking. Có lẽ rank cho một bộ phim nào đó từ 1-7 có trọng số tương ứng đi kèm. Có thể bài toán đi tìm kết quả tìm kiếm bộ phim phù hợp nhất đối với người dùng nào đó.
Click to access 13a.pdf
ThíchThích
Thầy! Theo em đọc thì em hiểu: Nếu phân 3 lớp: a, b, c ta sẽ chia theo công thức n*(n-1)/2 lớp con: (a,b), (b,c)(c,a). Nếu phân làm 4 lớp a, b, c, d ta chia làm 6 cặp theo công thức trên (a,b), (a,c), (a,d), (b,c), (b,d), (c,d). Nếu em có tập véc tơ đại diện cho 4 lớp (0 – 3) ví dụ như:
0 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
1 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
2 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
3 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
1 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
3 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
0 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
1 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
thì em sẽ chuyển như thế nào để đưa vào SVM chạy được Thầy. Em Cảm ơn Thầy. Rất mong Thầy giải thích giúp em.
ThíchThích
Em cần transform label sang dạng true/false hoặc 1/0 như bên dưới
0 vs all
1 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
0 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
0 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
1 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
1 vs all
0 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
1 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
0 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
1 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
0 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
1 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
2 vs all
0 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
0 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
1 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
0 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
0 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
3 vs all
0 1:1 6:1 14:1 22:1 36:1 42:1 49:1 64:1 67:1 72:1 74:1 77:1 80:1 83:1
0 1:1 6:1 17:1 19:1 39:1 42:1 53:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
0 2:1 6:1 18:1 20:1 37:1 42:1 48:1 64:1 71:1 73:1 74:1 76:1 81:1 83:1
1 5:1 11:1 15:1 32:1 39:1 40:1 52:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 5:1 16:1 30:1 35:1 41:1 64:1 67:1 73:1 74:1 76:1 80:1 83:1
1 5:1 6:1 15:1 20:1 37:1 40:1 50:1 63:1 67:1 73:1 75:1 76:1 80:1 83:1
0 5:1 7:1 16:1 29:1 39:1 40:1 48:1 63:1 67:1 73:1 74:1 76:1 78:1 83:1
0 1:1 11:1 18:1 20:1 37:1 42:1 59:1 62:1 71:1 72:1 74:1 76:1 80:1 83:1
ThíchThích
Em Cảm ơn Thầy. không cần tính xác suất cho các cặp hả Thầy.
ThíchThích
Sau khi train ra được k svm model. Em đưa dữ liệu test vào từng model để có kết quả phân lớp, model nào cho xác suất cao nhất thì mẫu dữ liệu này thuộc về lớp đó.
ThíchThích
Thầy có thể giải thích qua cho em cách chuyển được không Thầy.
ThíchThích
For i in range(0, 4): if line_str[0] == i: line_str[0] = 1 else: line_str[0] = 0
ThíchThích
Thầy có Tool nào về phân đa lớp trong SVM, dữ liệu mẫu nào về phần này không cho em tham khảo với ạ. Em cảm ơn Thầy.
ThíchThích
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/multilabel/
ThíchThích
Thầy có dữ liệu mẫu nào về phân đa lớp không Thầy (4 lớp) để em chạy thử nghiệm SVM. Em tải dữ liệu mẫu trên một số trang khi đọc trong libsvm-3.22 trong windows toán báo sai đầu vào Thầy.
ThíchThích
Em chào thầy em đang làm bài tập lớn về SVM , cho em hỏi là các ưu điểm và nhược điểm của SVM trong phân lớp là gì ak. em cảm ơn nhiều
ThíchThích
Em có thể tham khảo bài viết này
https://www.quora.com/What-are-some-pros-and-cons-of-Support-Vector-Machines
http://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
ThíchThích
Em đang làm đồ án nhận dạng số dựa vào thuật toán SVM. Em dùng đặc trưng haar để nhận dạng, nhưng em vẫn chưa hiểu làm sao để từ một cái hình có số đưa vào mà nó dựa vào SVM để nhận dạng. Xin thầy hãy giáp đáp tường tận giúp em với ạ. Em cảm ơn thầy!
ThíchThích
Em có thể tham khảo bài viết này https://gurus.pyimagesearch.com/lesson-sample-segmenting-characters-from-license-plates/
ThíchThích
Em chào thầy! Em đang làm phân lớp văn bản dùng: gSpan + SVM. Em đã có tập đồ thị phổ biến. Nhưng em vẫn chưa hiểu làm sao để chuyển dữ liệu sang dạng vector để đưa vào SVM để huấn luyện và phân lớp. Xin thầy hãy giải đáp giúp em với ạ. Em cảm ơn thầy!
ThíchThích
Chào thầy . Em đang làm đồ án về nhận diện cảm xúc . Ban đầu em chỉ trích những đặc trưng từ mắt và miệng rồi gắn nhãn cho nó như mặt buồn, vui , ngạc nhiên rồi đưa vào train trong libsvm . Nhưng em không biết tạo dữ liệu như thế nào để đưa những đặc trưng (mắt + miệng) từ 1 hình mới vào để lấy nghiệm là 1 label (buồn or vui or …) . Em cảm ơn , mong thầy giúp đỡ.
ThíchThích
Em có thể sử dụng mô hình Bag of Words
http://www.springer.com/cda/content/document/cda_downloaddocument/9783319056951-c2.pdf?SGWID=0-0-45-1450724-p176654764
Click to access icvss08_az_bow.pdf
Click to access Woodard.pdf
ThíchThích
Em đang làm về phân lớp văn bản, nếu em dùng SVM có được kết quả tối ưu nhất ko a. Em xin cảm ơn
ThíchThích
Em cần thực nghiệm để chọn ra mô hình cho kết quả tốt nhất. “No free launch theory”
ThíchThích
cho em hỏi trên bàn thầy ví dụ chỉ có bóng xanh, đỏ, giả sử có nhiều hơn vàng, tím… thì siêu phẳng xác định thế nào, hay chỉ tìm siêu phẳng cho từng cập màu quả bóng hả thầy.
ThíchThích
đúng rồi em, ta xét từng cặp bằng phương pháp One-Vs-All, nếu là Neural Network ta có thể output là số lượng classes phân lớp tương ứng
ThíchThích
Em Kính Chào Anh, Hiện tại em đang làm luận văn với đề tài ” Tối ưu lịch trình di chuyển của xe đến các trạm đón khách ” trong đó thì có nhiều yếu tố cần tối ưu ( tối ưu đa mục tiêu ) như là thời gian di chuyển, thời gian chờ đón khách, đón khách ở nhiều địa điểm khác nhau. Em có đọc một luận văn tương tự thì tác giả sử dụng PSO ( particle swarm optimization ) . Em xin hỏi liệu có thể sử dụng SVM để giải lại bài toán như trên để có kết quả tối ưu hơn được không?, bởi em thấy SVM dường như chỉ đang phân tách dữ liệu? thành công hay là thất bại. Em xin cám ơn .
ThíchThích
Về lý thuyết thì có thể, em cần tìm một hàm lỗi tương ứng và tiến hành optimize hàm lỗi này. Em có thể xem SVM ứng dụng vào regression https://en.wikipedia.org/wiki/Support_vector_machine#Regression
ThíchThích
Em chào anh,
Ở trên anh có nói: “Do ANN là representation model, ta không cần làm feature engineering như các model khác. Và các thuật toán trên chỉ mang tính chất tham khảo để ta dựa trên đó áp dụng vào bào toán của chúng ta. Ta không bó hẹp phạm vi ứng dụng mà có thể áp dụng vào nhiều lĩnh vực khác tuỳ thuộc vào khả năng sáng tạo của nghiên cứu sinh.”
Anh có thểcho em hỏi rõ hơn: representation model nghĩa là sao ạ?
Còn feature engineering ở các model khác là giai đoạn nào?
Em cảm ơn.
ThíchThích
representation model là đại diện cho tập dữ liệu đang xét. Ví dụ, mô hình linear regression dự đoán giá nhà khi cho đầu vào là diện tích nhà cũng là representation model, đó là đường thẳng hay đường cong cố gắng xấp xỉ với tập dữ liệu đang xét.
feature engineering thật chất cũng có tồn tại trong ANN, đó là khi em design số lượng node ở mỗi layer. Các model khác như ví dụ dự đoán giá nhà, nếu em có thêm thuộc tính chiều rộng, chiều dài, bên cạnh diện tích nhà thì rõ ràng các thuộc tính chiều rộng, chiều dài không độc lập tuyến tính đối với diện tích nhà. Lúc này em cần làm feature engineering để loại bỏ các thuộc tính phụ thuộc tuyến tính đó. Ngược lại, đối với ANN thì do cơ chế cập nhật qua mỗi bước backpropagation, thì giá trị node (feature) tại mỗi layer sẽ tự động hội tụ lại thành các thành phần vector độc lập tuyến tính mà không cần làm feature engineering.
ThíchThích
Thầy cho em hỏi trong tập huấn luyện có 1 cột toàn giá trị 0, nhưng tập test cột đó có 1 vài giá trị 1. Khi chạy trên R thì báo lỗi. can’t not scale data. Em phải sửa thế nào ah. Cảm ơn thầy
ThíchThích
em có thể thêm tham số scale = FALSE
http://r.789695.n4.nabble.com/Cannot-scale-data-td4663526.html
ThíchThích
Em để scale = FALSE thì độ chính xác giảm đi rất nhiều thầy ah.
ThíchThích
Thầy ơi, cho em hỏi độ phức tạp của thuật toán SVM này là như thế nào được không ạ?
ThíchThích
Đối với nonlinear SVM có độ phức tạp O(max(n,d) min (n,d)^2) với n là số lượng mẫu dữ liệu training, d là số chiều của tập dữ liệu đó.
Click to access libsvm.pdf
Click to access 021.pdf
Click to access 3601cc310d6cb6c8e22c144bbf29dce79150.pdf
ThíchThích
dạ, em cảm ơn thầy nhiều ạ. Cho em hỏi một ý nữa đó là: ví dụ bài toán của em tính toán đặc trưng hình ảnh và xuất ra mỗi ảnh là một giá trị vector gồm 32 phần tử trong đó. Vậy cái ảnh đó trong thuật toán đó chính là x trong công thức đúng k ạ?
Em vẫn chưa hiểu rõ giá trị đó thế như thế nào vào công thức :3, thầy giải đáp giúp em với ạ
ThíchThích
32 chính là d:dimension đó e
ThíchThích
Tại em mới nghiên cứu nó mà đọc tài liệu thấy có công thức w.x +b =0, em phân vân k biết thế cái 32 chiều đó ở chỗ nào :3. Thầy có tài liệu nào nói rõ về cái này không ạ?
ThíchThích
x là mẫu vector 32×1 đó e, e xem linear regression có cthuc nhu e đề cập
ThíchThích
Dạ, em cảm ơn thầy nhiều ạ
ThíchThích
Thầy ơi, cho em hỏi SVM tuyến tính và phi tuyến tính giống và khác nhau như thế nào ạ?
ThíchThích
Cả hai đều nói đến cách sử dụng kernel trong SVM.
Linear kernel: Polynomial
Non-linear kernel: Gaussian (RBF), Sigmoid
ThíchThích
Em chào thầy ạ. Em đang chuẩn bị làm đồ án tốt nghiệp. Thầy có thể gợi ý cho em một vài đề tài sử dụng phương pháp SVM để làm được không ạ
ThíchThích
bạn nên nói chi tiết hơn bạn đang học ngành gì, thạc sĩ hay tiến sĩ. trường nào. thì thầy sẽ dễ trả lời hơn .
ThíchThích
Hi em, về chủ đề thì em nên liên hệ giáo viên hướng dẫn đang nghiên cứu về lĩnh vực của họ nhé. Nhưng đầu tiên, em cần xác định mình thích làm với tập dữ liệu và bài toán nào: xử lý ngôn ngữ tự nhiên, thị giác máy tính, xử lý tín hiệu số, khai thác dữ liệu, …
ThíchThích
Thầy cho em hỏi về Kernel ạ và SVM sử dụng kernel như thế nào ạ?
ThíchThích
Cho em hỏi tại sao lại phải phân lớp bằng 1 đường thẳng (đối với trường hợp 2 chiều) và 1 mặt phẳng (đối với trường hợp 3 chiều) ạ? Phân lớp bằng đường cong hoặc mặt cong sẽ tốt hơn chứ ạ?
ThíchThích
đúng rồi e, thật ra theo công thức tổ hợp tuyến tính của các feature thì người ta gọi tên là “hyperplane” nghĩa là siêu phẳng, mặt phẳng trong không gian nhiều chiều.
Mặc dù, trong không gian 3 chiều, ta thấy đây là một mặt phẳng nhưng khi chiếu xuống không gian 2 chiều thì mặt cắt phân lớp này lại tạo ra hình tròn, đường cong hay đường hình học nào đó khác đường thẳng, giúp phân lớp chính xác tập dữ liệu huấn luyện.
ThíchThích
Cho em hỏi thay, SVM co the phân lớp (classify) tập dữ liệu thành 3 lớp riêng biệt không thay?
ThíchThích
Ko em, em phai chuyen qua bai toan multi-classification
ThíchThích
cảm ơn bài viết của anh rất nhiều. Tôi sử dụng SVM để giải quyết bài toán phân loại biến quan trọng (important variables) để input vào mô hình Random forest, kết quả phân tích bằng phần mềm XLSTAT như sau:
Performance metrics (Logistics – 0 / 1):
Statistic Training set Validation set
Accuracy 0.813 1.000
Precision 0.805 1.000
Recall 0.993 1.000
F-score 0.890 1.000
Specificity 0.061 0.033
FPR 0.939 0.967
Prevalence 0.753 0.967
Cohen’s kappa -2.369 0.000
NER 0.758 0.967
AUC 0.790 1.000
Anh có thể giải thích giúp ý nghĩa và kết quả phân tích ở trên được không?
Cảm ơn anh nhiều,
ThíchThích
đây là một số metrics để đánh giá các mô hình classification, bạn có thể tham khảo ở đây nhé https://ongxuanhong.wordpress.com/2015/08/25/danh-gia-mo-hinh-model-evaluation/
ThíchThích